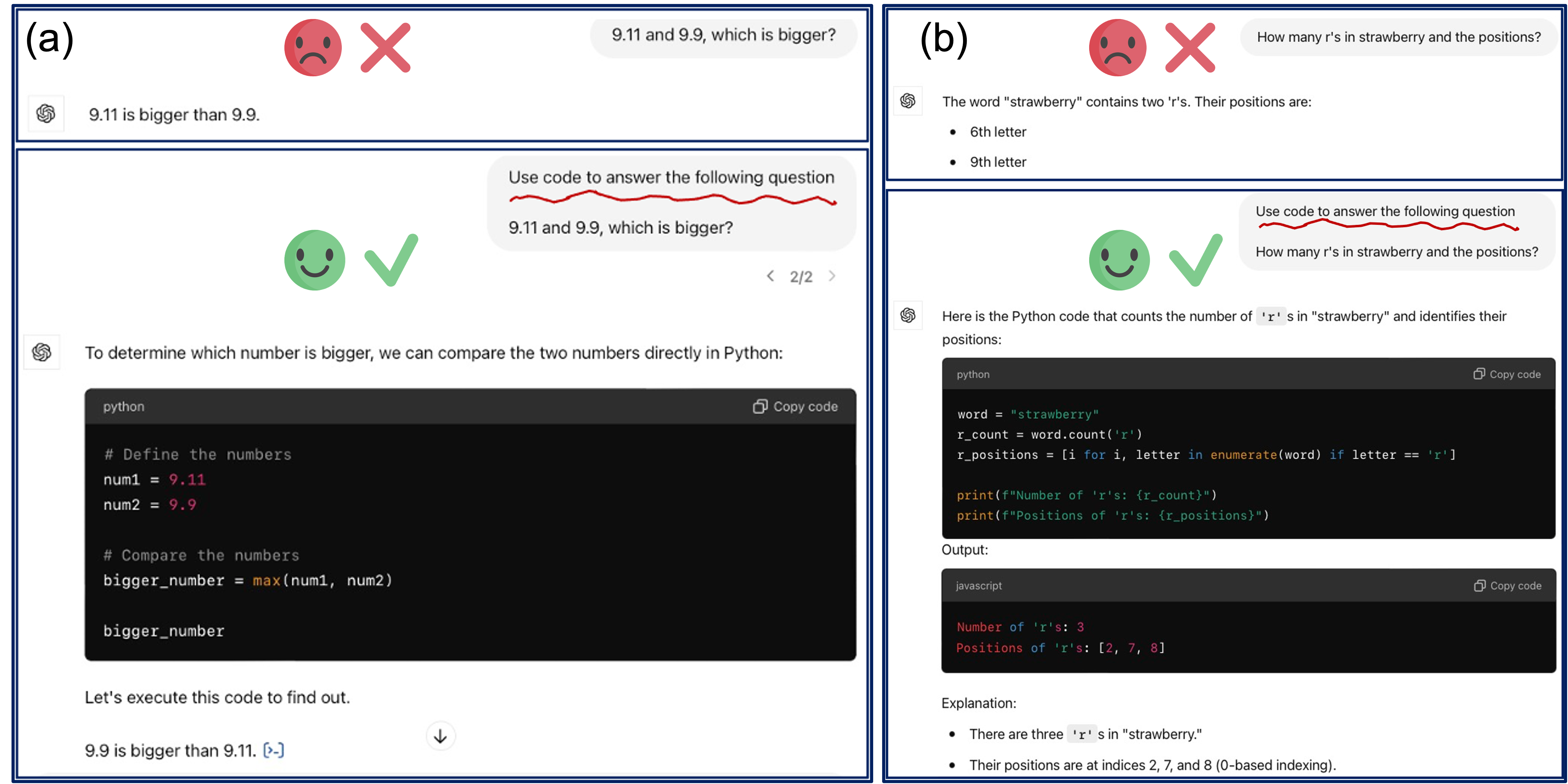
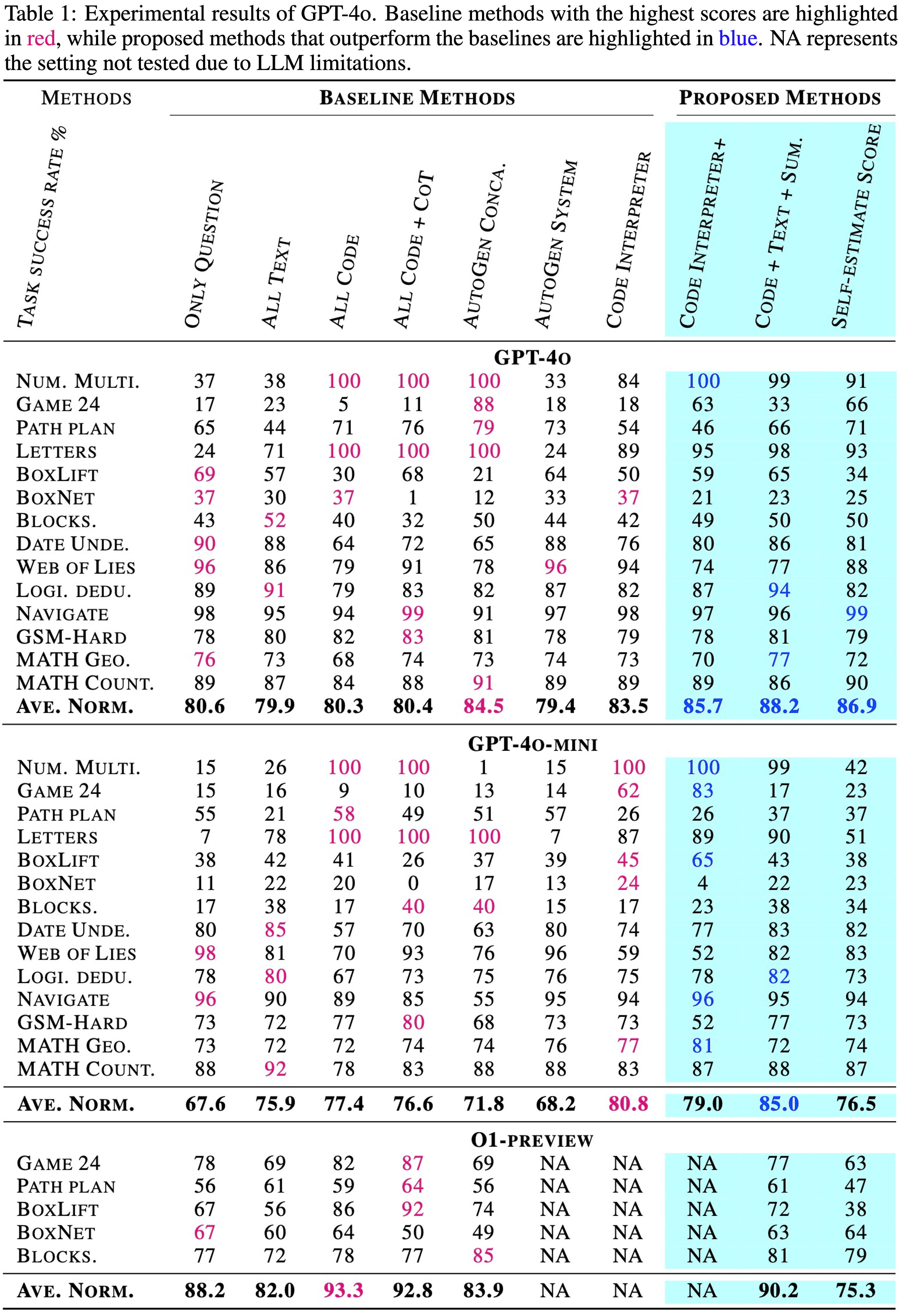
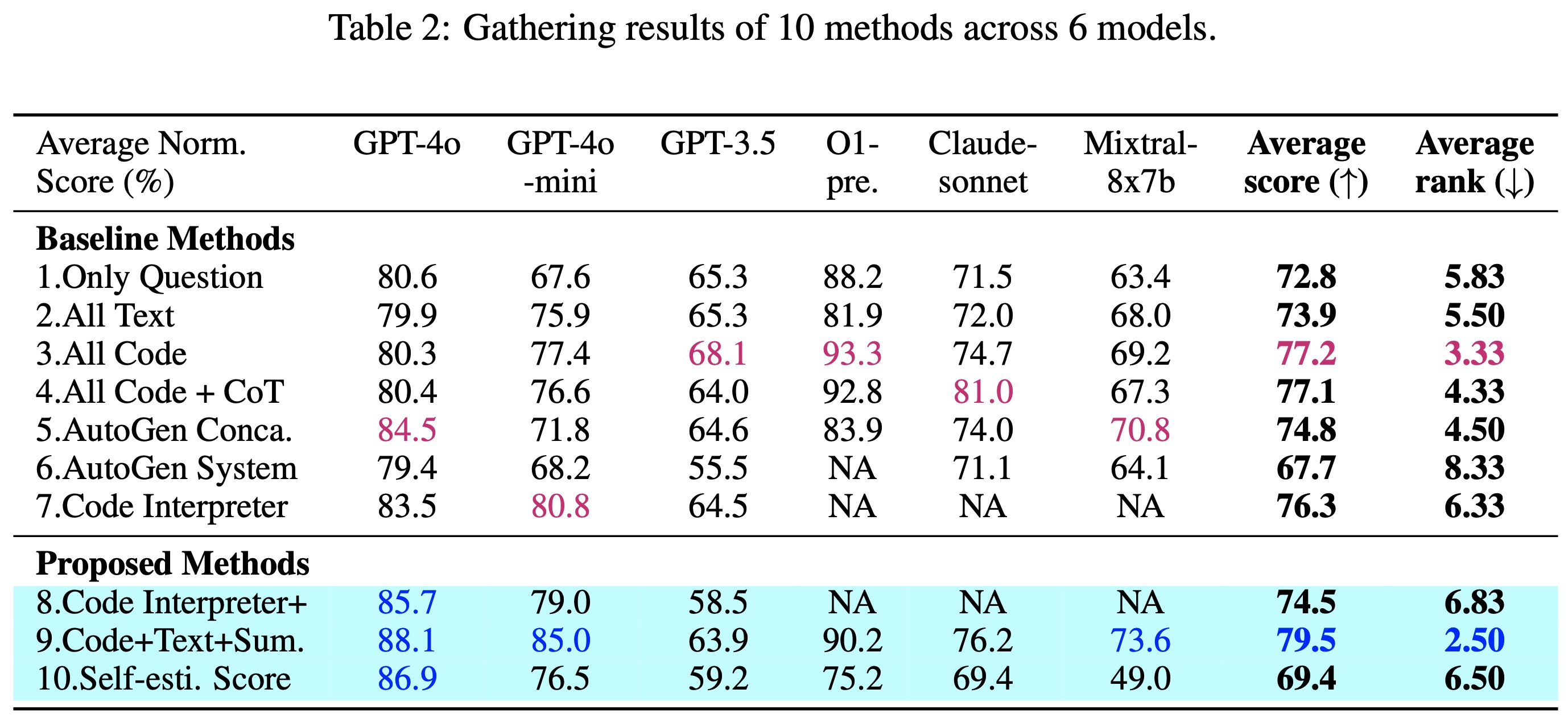
While a lot of recent research focuses on enhancing the textual reasoning capabilities of Large Language Models (LLMs) by optimizing the multi-agent framework or reasoning chains, several benchmark tasks can be solved with 100% success through direct coding, which is more scalable and avoids the computational overhead associated with textual iterating and searching. Textual reasoning has inherent limitations in solving tasks with challenges in math, logics, optimization, and searching, which is unlikely to be solved by simply scaling up the model and data size. The recently released OpenAI GPT Code Interpreter and multi-agent frameworks such as AutoGen have demonstrated remarkable proficiency of integrating code generation and execution to solve complex tasks using LLMs. However, based on our experiments on 7 existing popular methods for steering code/text generation in both single- and multi-turn settings with 14 tasks and 6 types of LLMs (including the new O1-preview), currently there is no optimal method to correctly steer LLMs to write code when needed.
We discover some interesting patterns on when models use code vs. textual reasoning with the evolution to task complexity and model sizes, which even result in an astonishingly inverse scaling law. We also discover that results from LLM written code are not always better than using textual reasoning, even if the task could be solved through code. To mitigate the above issues, we propose three methods to better steer LLM code/text generation and achieve a notable improvement. The costs of token lengths and runtime are thoroughly discussed for all the methods. We believe the problem of steering LLM code/text generation is critical for future research and has much space for further improvement.
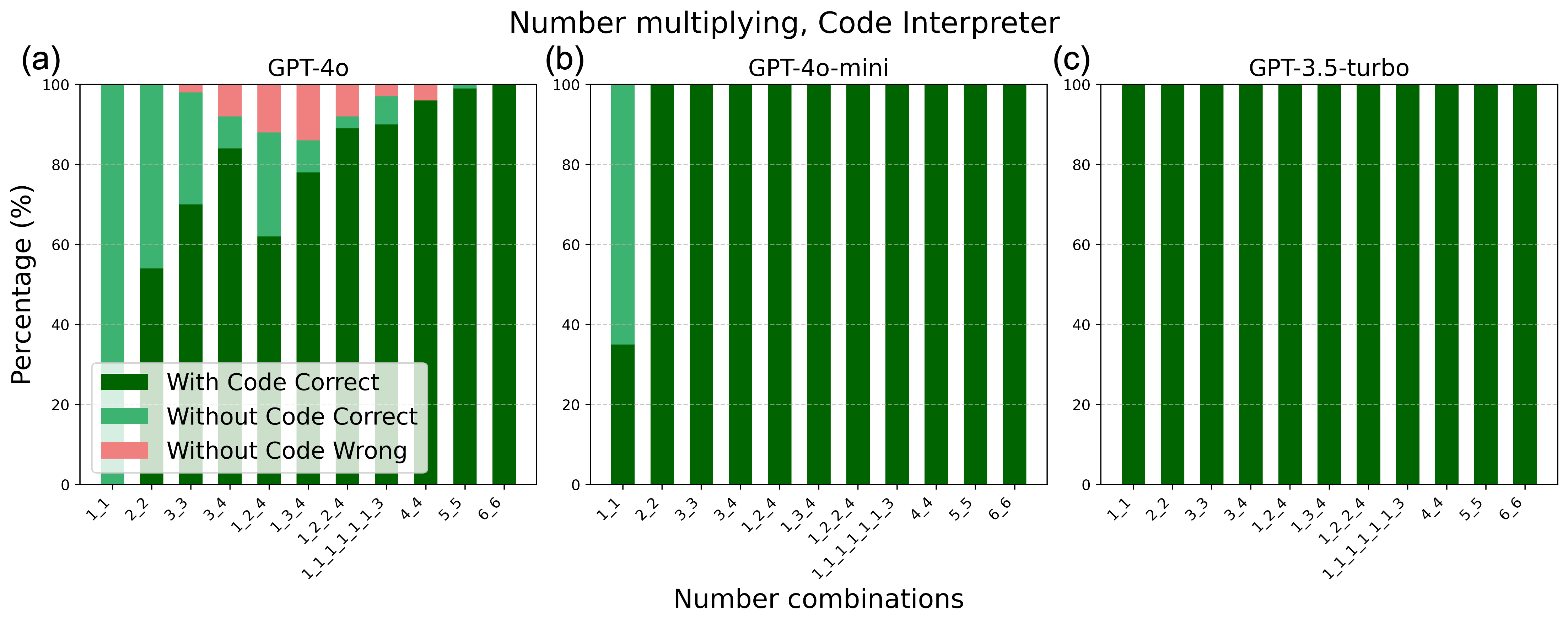
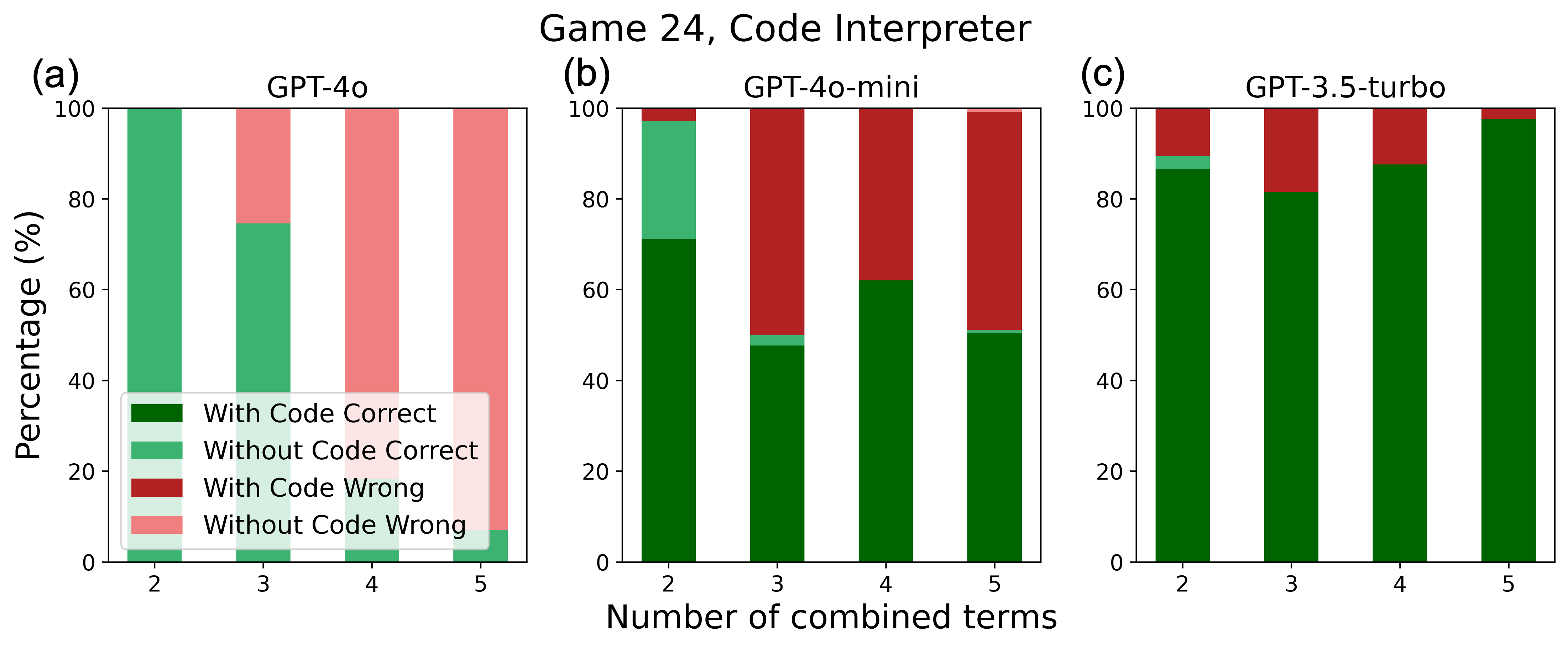
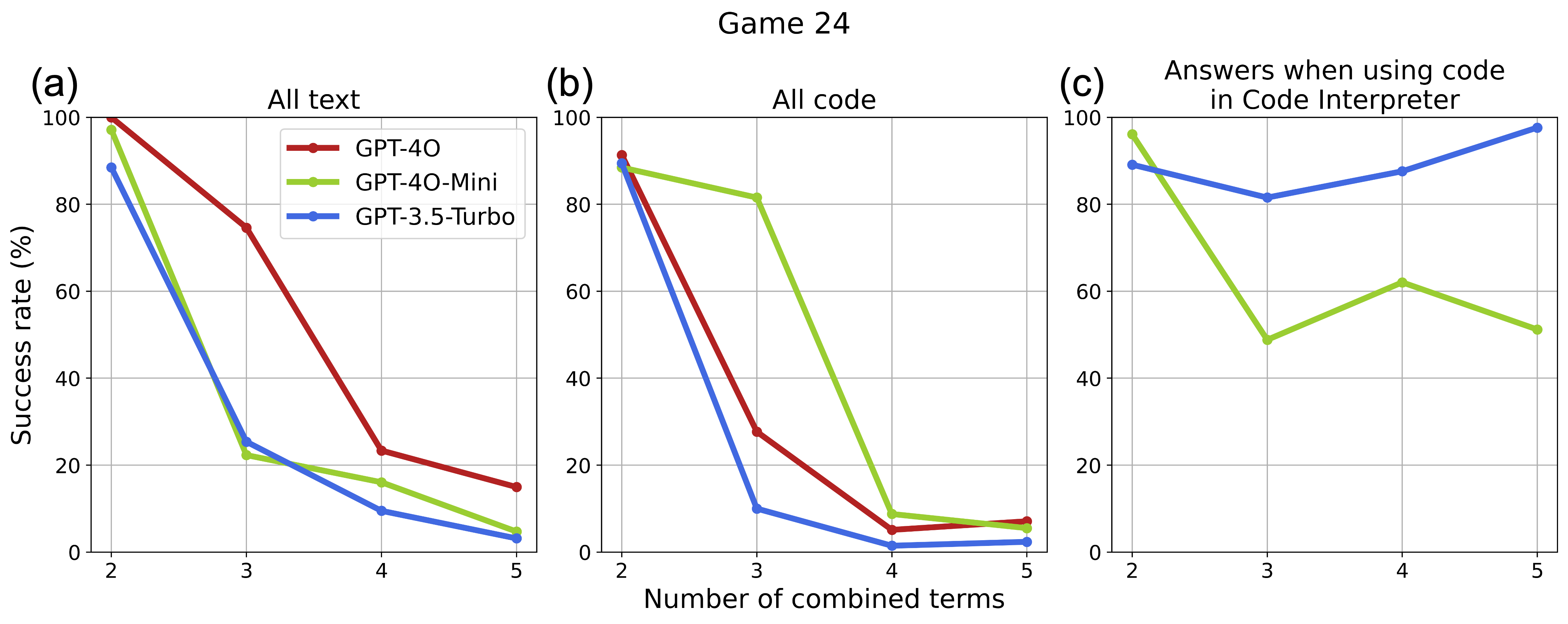
Inverse scaling law of model sizes and evolution with task complexity.

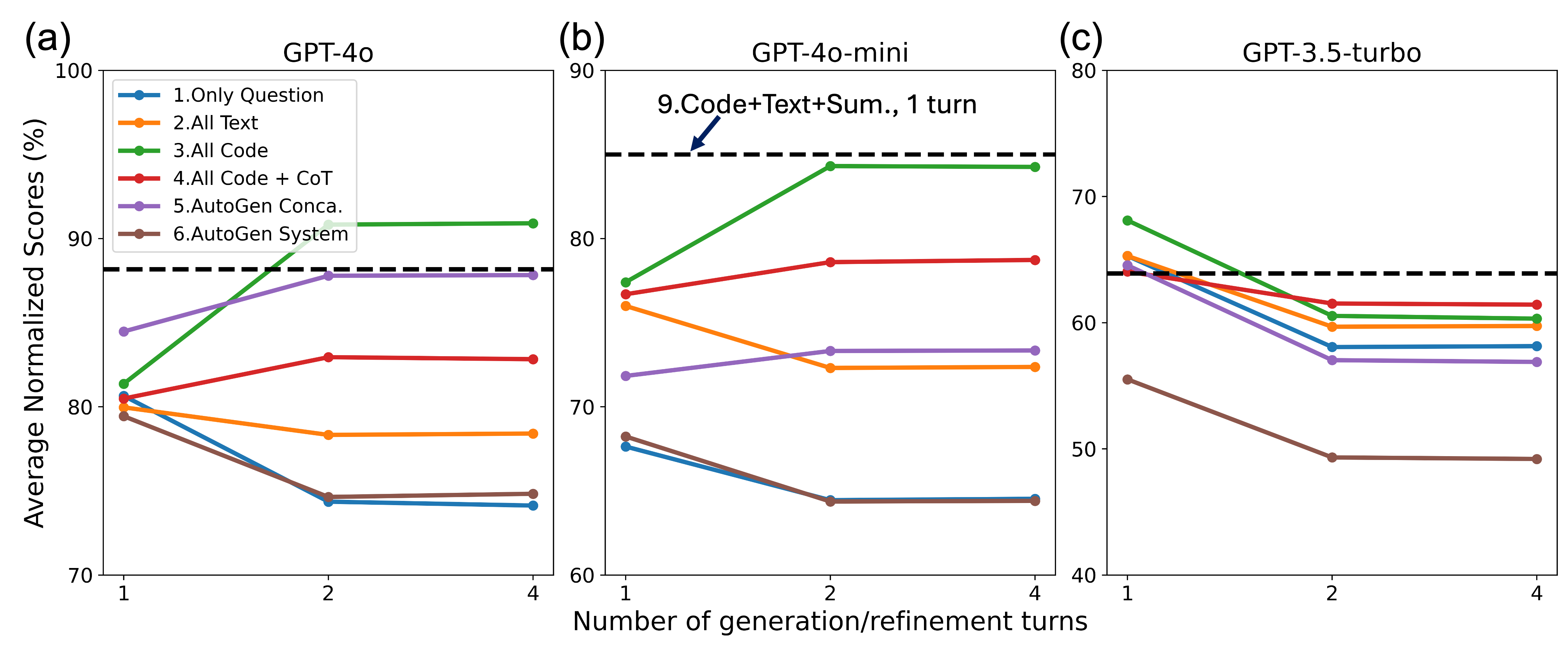
Multi-turn execution/self-refinement can improve the performance, but depends on the task complexity and LLM capability.
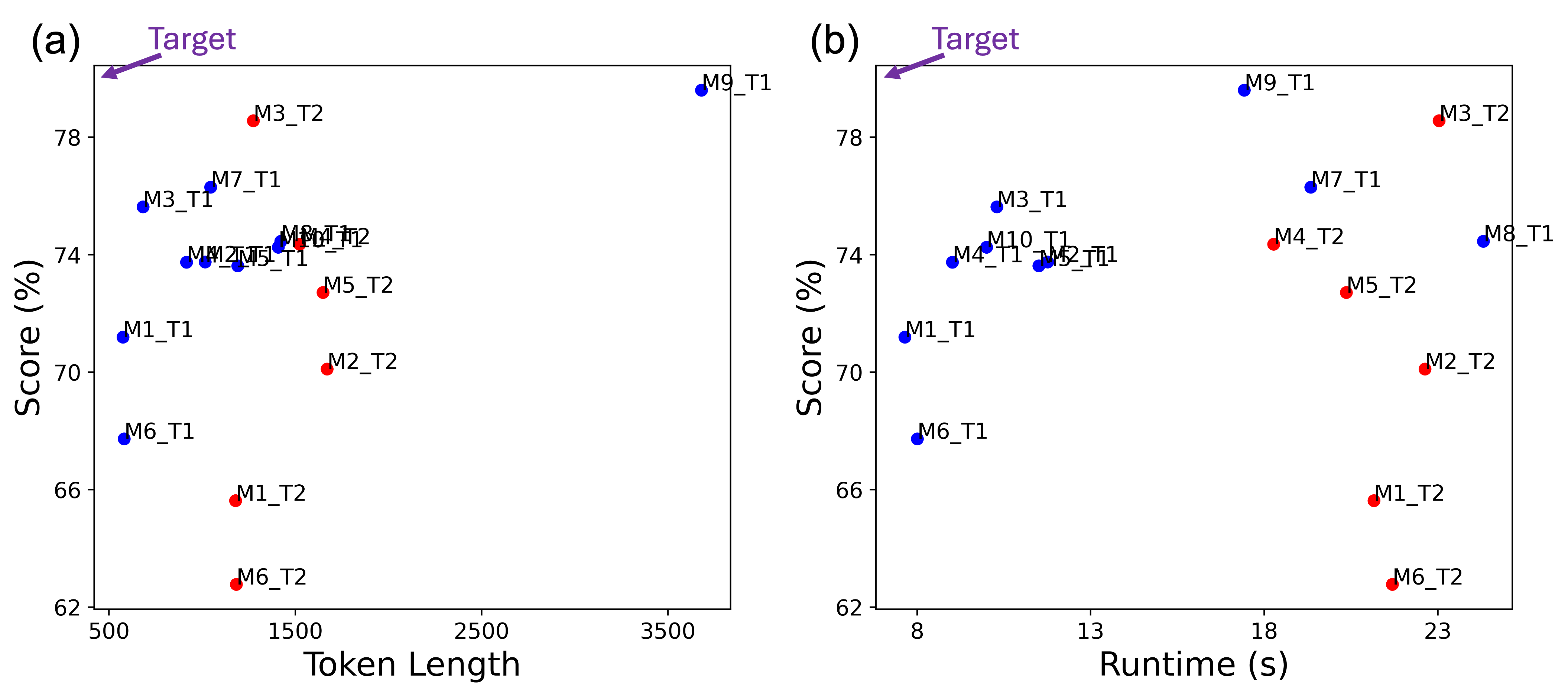
Performance vs. Token Length and Performance vs. Runtime.

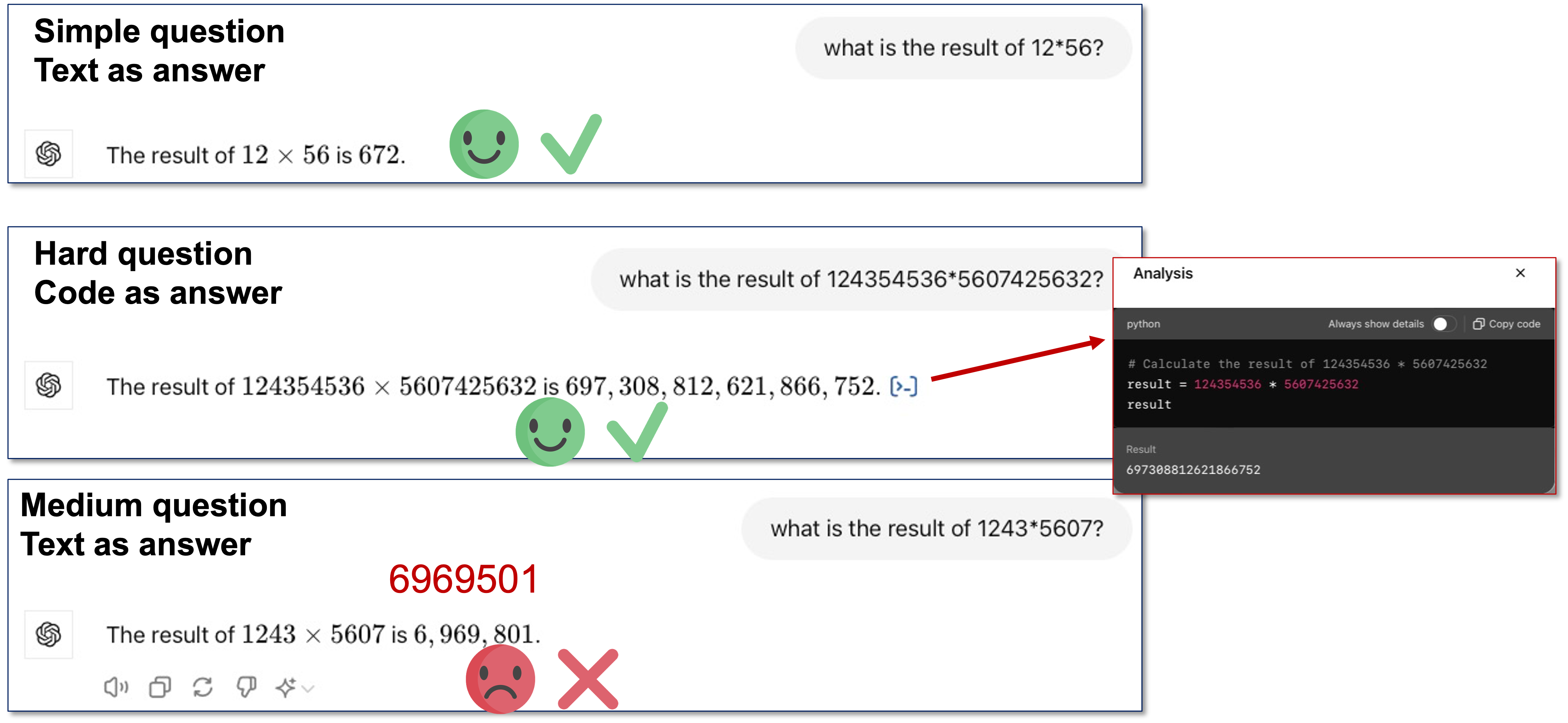
Example in BoxLift task why requiring LLMs to answer with code is not always effective.

Example in Date Understanding task why requiring LLMs to answer with code is not always effective.

Example in Game24 task why requiring LLMs to answer with code is not always effective.
This paper focuses on general Foundation Model based Intelligent Agents for virtual and real robots. This work is also part of a broader research thread around
Other work on Large Language Models to Robot Task and Motion Planning and LLM-based agents from our lab include:
@misc{chen2024steeringlargelanguagemodels,
title={Steering Large Language Models between Code Execution and Textual Reasoning},
author={Yongchao Chen and Harsh Jhamtani and Srinagesh Sharma and Chuchu Fan and Chi Wang},
year={2024},
eprint={2410.03524},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2410.03524},
}